Improving a SaaS Codebase's Health by Refactoring
How git archaeology, an Eisenhower matrix, and a disciplined testing strategy turned a grinding codebase into a maintainable one.

A SaaS dev team had reached a familiar point with their codebase. What was once a fast-moving codebase, over time, had accumulated enough shortcuts that the shortcuts themselves became the architecture. New features took weeks longer than they should. Bugs were difficult to trace because the same logic lived in multiple places with only a slight variation each. A new developer meant onboarding consists of weeks of tribal knowledge transfer. And certain files had developed a reputation where nobody wants to touch them because they always cause the most bugs.
In this document, I’ll describe how I approached a two-month refactoring consultation on their Django and React codebase, from initial analysis through to a measurable reduction in bugs and a test suite that went from zero to 50% coverage.
Disclaimer: This post looks at the architecture in a high-level manner, and is intentionally generic to not disclose any client-specific information. Certain details such as networking specifics and code-level architecture are omitted for brevity.
Background
The SaaS application is a Django backend with a React frontend at around ~70k LOC. The codebase had grown organically over several years with copy-paste reuse being the dominant technique to get features out quickly. When a module needed to serve a slightly different purpose, it was duplicated and modified rather than abstracted. Over time, this meant that a fix or an update in one place needed to be manually replicated across several others. Without tests, all these places aren’t usually covered and caused subtle bugs.
The symptoms were all present at once:
- Bug reports were coming in at roughly 35 per week, many of them the same class of issue: an update was made to one module but not to its copies elsewhere.
- New features were slow to ship because developers had to understand several modules (which are near-identical) before making any change with confidence.
- Test coverage was effectively zero, which meant there was no safety net for refactoring, and no automated way to verify that a change hadn’t broken something else.
- Onboarding was painful — there was no single source of truth for how the system worked.
Analysis
Finding the Hotspots
Not all code are equal. A module that has been untouched for two years is a very different problem from one that five developers have modified forty times in the last quarter. The first thing I wanted to understand was where in the codebase do developers do the most work on.
To do this, I ran a git log analysis to extract the files most frequently touched in the past year:
git log --format=format: --name-only --since=12.month \
| egrep -v '^$' \
| sort \
| uniq -c \
| sort -nr \
| head -50
This identifies the top 50 files by commit frequency over the last year. The result is a ranked list of where developer effort has actually been concentrated.
Several modules that the team had flagged as critical were barely touched. The authentication module, which the team expected to rank highly given its perceived importance, appeared far down the list. This shows an important distinction that became a recurring theme in stakeholder conversations: code usage is not the same as how often code changes. A heavily-used module that is stable carries different risks compared to a heavily-used module that is constantly being modified.
Prioritizing with an Eisenhower Matrix
The next step was to map how much business value or risk was associated with each module. I plotted the hotspot data into an Eisenhower matrix using two axes: importance (business criticality, user-facing impact) and urgency (how frequently the code was being touched and therefore how much pain it was actively causing).
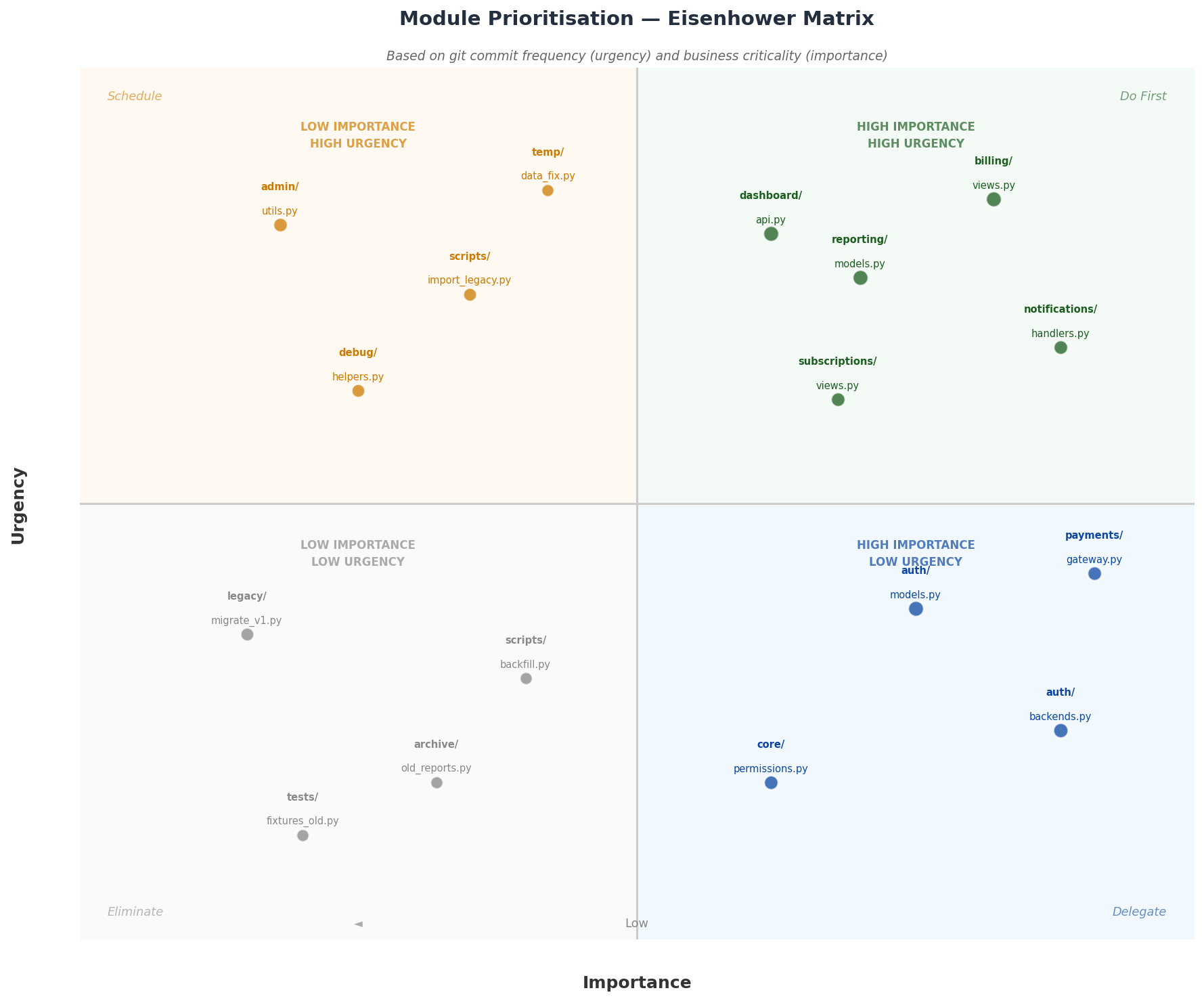
This gave us four quadrants to reason about:
- High importance, high urgency — These modules cause the most pain right now. Being high stakes, these became the primary focus of the refactoring effort.
- High importance, low urgency — Stable but critical. These warranted careful documentation and monitoring, but not immediate refactoring.
- Low importance, high urgency — Frequently changed but not business-critical. These were candidates for cleanup but can be deferred later.
- Low importance, low urgency — Left alone entirely.
Discussing the matrix with the stakeholders created a shared, evidence-based vocabulary for prioritization. The auth module was a good example: the team had assumed it would be a priority, but the data showed it was stable. That freed up focus for modules that were genuinely causing negative impact on delivery time.
Refactoring Strategy
Testing Pyramid
The core challenge of refactoring a codebase with zero test coverage is that you have no way to verify you haven’t broken anything. Unit tests are short to write, but they test isolated behavior by design. They won’t tell you if the system as a whole still works after a refactoring session. Besides, most codebase that don’t have any tests are not testable by design, making unit testing a bit tricky to start off.
Instead, I followed a deliberate progression: E2E tests first, then integration tests, then unit tests.
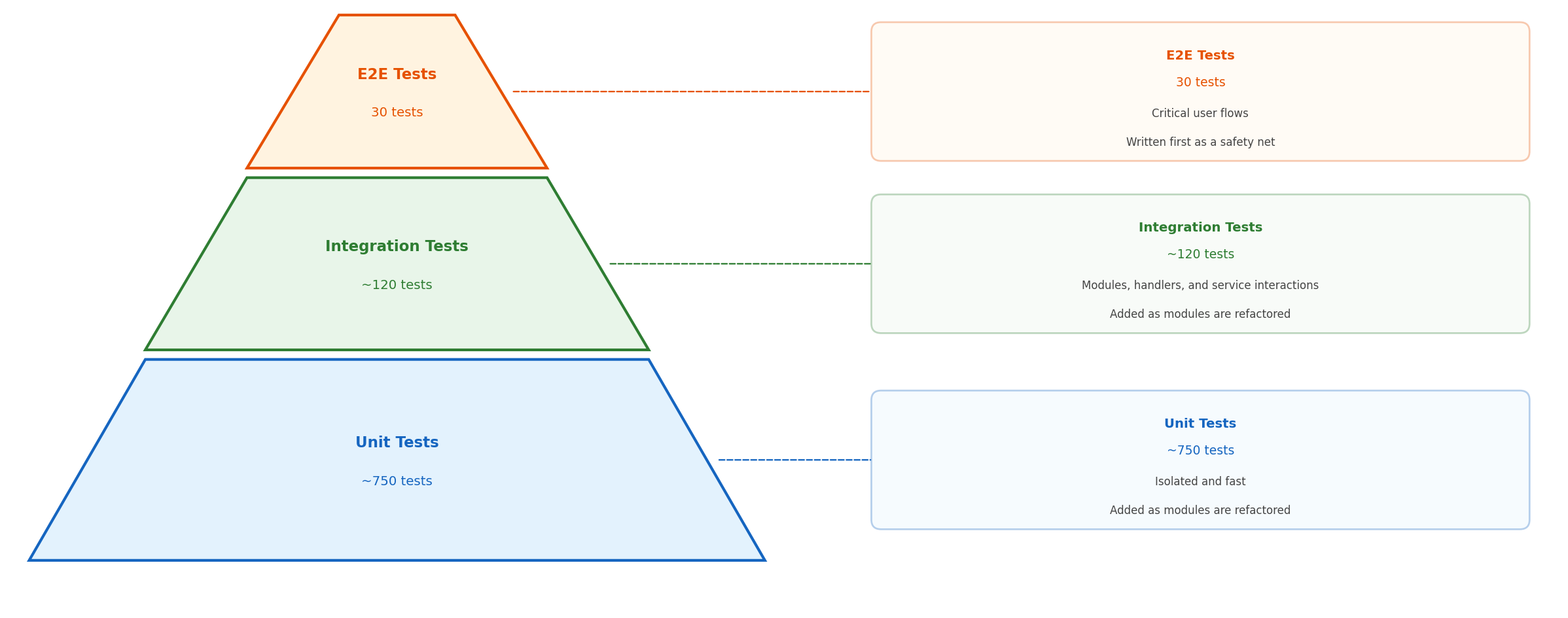
While E2E tests are a heavier investment, sometimes they are the only way into a codebase without any tests. Covering the key, business-critical flows are crucial to make sure functionality is preserved across refactoring sessions. Once E2E tests are in place, a larger number of integration tests are used to cover the internals. These would then serve as a safety net for unit tests once we reshape onto better design.
This approach made sure that we are refactoring safely.
Addressing the Copy-Paste Architecture
A main problem was that shared logic had been duplicated rather than abstracted. The biggest consequence of this was the class of bugs that appear when a module change doesn’t propagate to its copies. This makes the system behave correctly in one context, but incorrectly on another, without an obvious connection between the two.
The refactoring consolidated these duplicated modules into single, well-tested abstractions. The prioritization from the Eisenhower matrix meant the most touched modules that carry the most importance are the ones that get worked on first, resulting in lesser friction for the dev team as the refactoring sprints went on.
Results
After 2-months of work and a 1-month testing pilot:
- Bug reports dropped from approximately 35 per week to 10 per week — a reduction of over 70%.
- The copy-paste bug class was eliminated entirely during the pilot period.
- Test coverage went from zero to 50%, concentrated on the highest-priority modules.
- Developer confidence improved measurably. Files that had previously been avoided were now covered by tests, allowing developers to work on them without fear of breaking existing functionality.
Conclusion
In this post, we explored how using git history during the discovery phase can provide insight on where refactoring effort should go. Paired with a disciplined testing progression, refactoring itself could proceed safely even from a standing start with no existing test suite.
At a glance:
- Bug reports reduced from ~35 to ~10 per week (~70% reduction)
- Copy-paste bug class eliminated entirely in the 1-month pilot
- Test coverage raised from 0% to 50% in two months
- Codebase hotspots identified and prioritized using git log analysis
- Stakeholder alignment achieved through an Eisenhower matrix
Future Improvements and Retrospective
One of the most useful lessons from this consulting was around the framing of refactoring to stakeholders. There was a natural bias against the initiative as refactoring doesn’t ship features. And anything that doesn’t ship features is hard to justify to a business. To help build momentum, I proposed a short feature freeze to concentrate effort at the start of the initiative. The freeze lasted three days and gave the team the space to get the initial E2E suite in place and establish the working patterns for the refactoring.
In hindsight, I should have made it clearer upfront that the freeze was a “nice to have” but not a necessity. E2E tests in particular are not disruptive to add as they run against the application and don’t require touching production code. If I have had framed the E2E testing as an investment that is independently valuable (a good idea regardless of whether a refactoring is happening), I believe the stakeholders would have had more confidence in the timeline.
I now frame this way: a well-placed E2E test suite is an asset that pays back immediately in reduced regression. The refactoring effort just gives us a reason to write the test suite now rather than later.