Migrating a Django app from a VPS to AWS
Saving costs and improving reliability by utilizing AWS services.

A SaaS in the Human Resources tech space had steadily grown its client base by being able to iterate fast and deliver new features quickly. However, their single VPS began driving up costs due to frequent vertical scaling for memory and disk needs. At the same time, their manual deployment process introduced 15–30 minutes of downtime per release. This led to a culture of “deployment fear” where developers try to postpone deployments as much as possible, which snowballs to bigger batch sizes that further amplifies the problem.
In this document, I’ll describe how I helped rearchitect their application and deployment process, with the main goals of improving reliability and cost efficiency.
Disclaimer: This post looks at the architecture in a high-level manner, and is intentionally generic to not disclose any client-specific information. Certain details such as networking specifics and code-level architecture are omitted for brevity.
Background
The SaaS application is a monolithic Django application backed by a PostgreSQL database. The app is hosted in a single VPS box, which also contains auxiliary services. The following diagram illustrates the components of the original architecture:
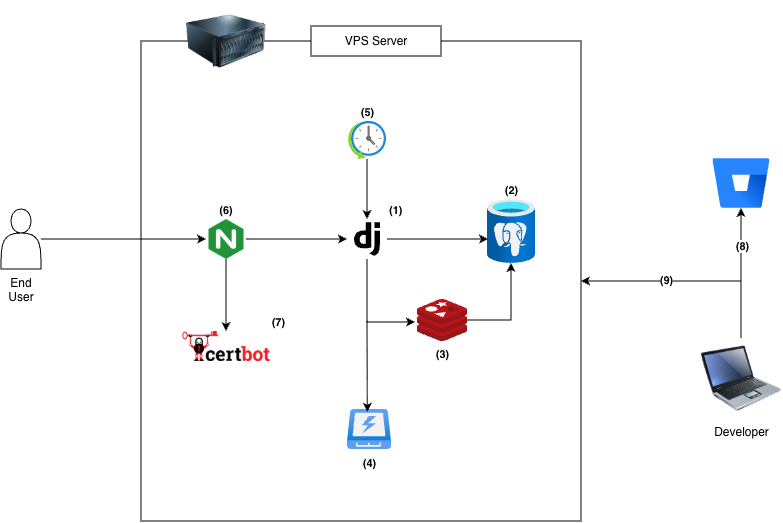
- Application logic is written in Python and utilizes the Django web framework.
- Data persistence is facilitated by PostgreSQL.
- Redis serves a dual purpose as a cache for frequently accessed data and as a job queue for code that can be handled outside the HTTP request/response cycle.
- User uploaded files and static assets are stored on disk.
- Periodic and maintenance scripts are executed via
cron. - HTTP traffic is received by Nginx that acts as a reverse proxy.
- SSL certificates are provided by Certbot.
- Source code is hosted in Bitbucket.
- A senior engineer SSH’s into the server, runs
git pull, and runs a script to restart the application. This constitutes a deployment.
System Migration
As their client base grew, the company needed a more cost-effective way to host their SaaS application. They also needed to move away from their current deployment process as downtime had increased due to frequent human error when executing the manual steps. The goal was to be able to iterate on new features without the system architecture getting in the way.
Let’s look at the migration in two sections: the system architecture and the CI/CD pipeline.
System Architecture
We’ve decided to move their setup onto Amazon Web Services (AWS) to better utilize specialized services, reducing the responsibility of a single VPS.
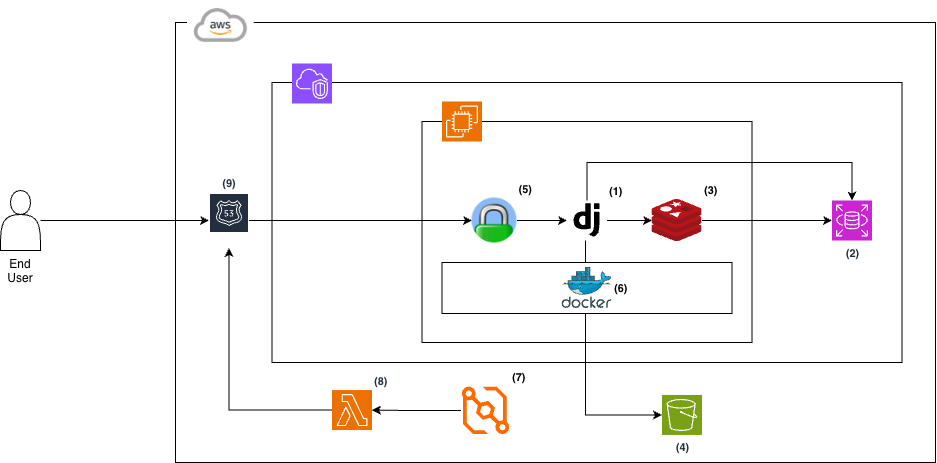
- Application logic in Django is kept as-is.
- Data persistence is offloaded to an Amazon RDS for PostgreSQL instance to better utilize its automated backups, point-in-time recovery, and abstract away database server management tasks.
- Given the size of the data being processed and the cost-sensitivity of the initiative, we have determined that keeping the Redis cache on the Amazon EC2 instance is enough.
- Media and static files are now written to a dedicated Amazon S3 bucket, reducing the burden of managing the files on disk.
- Caddy replaced Nginx as the reverse proxy as it facilitates built-in automatic SSL renewal. The dev team also agreed that the Caddyfile syntax is much easier to understand.
- All the services are being run as Docker containers.
- The
cronschedule was moved to Amazon EventBridge. - An AWS Lambda function is triggered periodically, and it hits an internal API endpoint on the webapp to trigger maintenance tasks.
- DNS records are managed by Amazon Route 53.
After a few months of operation, the new AWS setup had comparable costs with the old VPS setup (~$230 vs ~$200) as we had enough data to right-size the EC2 instance. This compensates for the additional cost of the RDS database. The decision to keep Redis on EC2 was primarily driven by cost. Cache durability was not a business requirement, making a managed service like Amazon ElastiCache unnecessary at this stage.
While horizontal scaling was not a business requirement at the time, we deliberately kept the application layer on a single EC2 instance. This preserved the team’s familiar vertical scaling model while still allowing us to decouple stateful components like the database and file storage. As the services are now running on Docker, this should provide a foundation for further containerization efforts (such as moving to Amazon ECS) if needed.
We leveraged an existing Lambda pattern used in another project to minimize implementation time and avoid introducing new scheduling complexity inside the application layer.
While not totally removing the impact of the EC2 instance being a “single point of failure”, this reduced the operational blast radius and enabled future horizontal scaling by decoupling the persistence layer.
CI/CD Pipeline
Having only a production environment and developers doing manual commands to deploy is a very risky practice for an organization. Developers can only rely on their local environment to verify their work, and a single misstep on the deployment procedure could pull down the SaaS application. A reliable CI/CD pipeline is crucial in ensuring quality work flows from development to production.
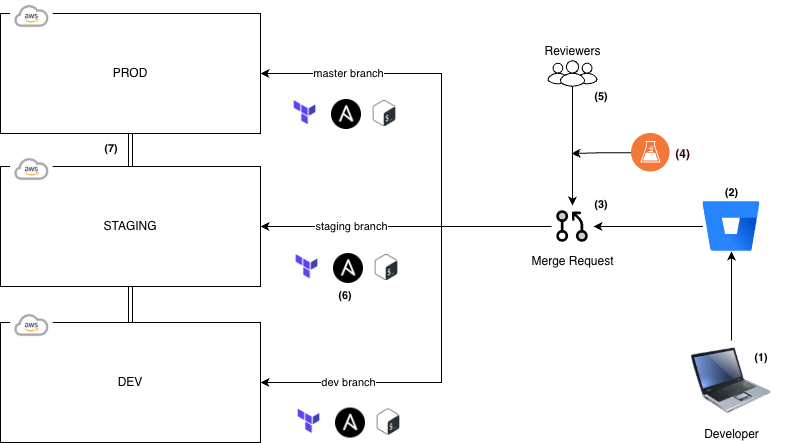
- A developer works on a feature on a local environment on their machine. As we’ve migrated to using Docker containers, this makes local environments much closer to prod.
- Frequent commits are made to their branch and pushed to Bitbucket.
- Once ready, a merge request is opened.
- Automated tests and quality checks are run for each MR. Any failure blocks the MR from being merged.
- A set approval rules are enforced to make sure MRs are properly reviewed. These rules are relaxed on lower environments to facilitate self-serving.
- Once merged, shell scripts that trigger Terraform and Ansible code are run to properly configure the infrastructure and the EC2 instance.
- Special branches are used to control deployments onto different environments:
devcan be used for general dev testing.stagingis used for official QA work.masterequates to the production environment.
Terraform allows infrastructure to be defined as code, which allows code management techniques (version control, code reviews) to be applied. As BitBucket is already used, it is the natural choice for CI/CD capabilities. As Ansible is already used in an adjacent project, we decide to use it for instance configuration. This leads to clear separation between infrastructure provisioning and configuration.
Merge request rules are added to control the quality of new features, ensuring a baseline quality that can be built on top of. As the organization structure is flat at that time, we decided to keep a simple “requires 3 people to approve” rule.
Distinct, specialized environments for various purposes without affecting prod are now available. Manual steps (aside from merge request approval) are also completely removed. This results in less downtime due to deployment issues (15-30 minutes per deploy to none reported in the 3-month pilot window), which led to increased confidence from the developers and stakeholders.
Conclusion
In this post, we explored how rearchitecting a traditional VPS-based application onto AWS can provide cost-savings and enhanced reliability by utilizing specialized services to handle non-core workloads. We also explored how a CI/CD pipeline can improve code quality and accelerate development by providing a safe mechanism for deployment.
The SaaS now has reduced deployment risks, elevated organization confidence, and future readiness to handle scaling needs.
At a glance:
- Deployment downtime reduced from 15–30 minutes to zero in 3 months
- Infrastructure cost remained comparable (~$230 vs ~$200)
- Manual SSH deployments eliminated
- Introduced dev/staging/prod isolation
- Enabled future horizontal scaling
Future Improvements and Retrospective
Leading this initiative had given me valuable insight on how to migrate a traditional VPS application. Because cost-efficiency and reliability were core requirements, careful tradeoff analysis was critical to ensure long-term operational simplicity.
One such tradeoff was deliberately postponing ECS adoption, even though containerization would make it a natural next step. I’ve considered that while ECS could provide a lot of heavy lifting as a managed service, horizontal scaling is not a top priority at the time. Plus, it is a different model than what the team is confident with while an EC2 is still like a “familiar VPS”.
As I’ve observed the team’s workflow, the special branch deployment model had been an obvious choice at the time. If time had permitted, I should’ve considered a version-based workflow where build artifacts can be generated on-demand per merge request. These versioned artifacts can then be deployed independently to each environment, reducing the need to maintain long-lived special branches.